论文:FoveaBox: Beyond Anchor-based Object Detector
论文链接:https://arxiv.org/abs/1904.03797
代码链接:https://github.com/taokong/FoveaBox
Introduction
FoveaBox同样是一篇Anchor Free的文章,与之前介绍的Anchor Free文章不同,FoveaBox并不是通过关键点检测来实现,其思想有点类似DenseBox与YOLOv1,Anchor-based的思想是通过预定义一些Anchor(候选框)去与Groundtruth做比较,得到候选框相对GroundTruth的偏移量,而FoveaBox则将候选框移除了,得到的Feature map对每个pixel预测其分类与候选框的坐标,几乎就是暴力回归。与其他的Anchor free的文章一样,该文章指出Anchor based文章有以下三个问题:
- 会带来不少的超参数(anchor的个数、比例等等)
- 对于不同的数据集,需要设计不同的anchor的尺寸和比例,泛化能力较差(类似YOLOv3通过聚类得到anchor的大小)
- anchor机制会导致正负样本不平衡的问题
上述的问题,也确实是Anchor机制导致的问题,相信大家也听过不少了,解决方法要么是提出能够自适应的Anchor,要么放弃Anchor,投入Anchor-free的怀抱。
Method
Architecture

首先我们来看看FoveaBox的整体框架是怎样的(见上图),是不是很熟悉,这不是和RetianNet一致的框架么。不同的地方就在与(原文作者也标红了),最后一层的feature map的通道数不相同,RetinaNet是W x H x KA和 W x H x 4A,而FoevaBox则是W x H x K和W x H x 4,其中K表示数据集中物体的类别数(COCO - 80, VOC - 20)而A表示 Anchor的数目,FoevaBox摒弃了Anchor,因此channel数自然少了A倍。
Scale Assignment
由于不同的物体,尺度变化较大,作者借鉴了FPN的思路,FoveaBox将连续尺度划分成多个区间,并将它们和特征金字塔中的不同层对应。因此,特征金字塔中每层只负责预测某个特定尺度范围的矩形框,其中Sl表示第l层特征的基础大小,而给定的区间范围由一个系数η控制,衡量方式如下二式所示:
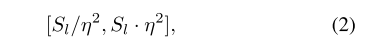
其中值得注意的是某个尺寸的物体可能会被映射到金字塔不同层次,这与之前FPN的概念有差异(某尺寸只被映射到金字塔特定某层)。
Object Fovea
Fovea其实就是依据ground truth 在输出的特征上制定的样本区域。给定一个ground truth的坐标(X1,Y1,X2,Y2),首先将这个矩形框映射到其对应的金字塔层
可以看到就是将image上的矩形框的坐标点映射倒FPN输出的每个Feature map上。得到GT映射到Feature map的中心点坐标后,作者通过以下的变换确定中心区域。
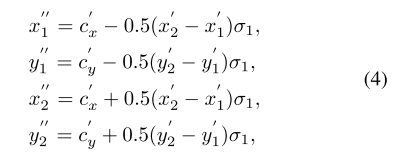
FoveaBox需要对特征图上每个点都预测一个分类结果以及并回归边框的偏移量,由于物体真实边框附近的点远离物体中心,或者与背景像素更为接近,如果将其作为正样本,对模型的训练造成困难。因此作者通过一个简单的变换,先通过groundtruh边框得到物体中心在特征图中对应的位置,然后通过一个参数σ1调节物体高和宽,将用来训练的真实边框位置向物体中心收缩一点,收缩后的边框内部的点作为正样本,然后使用参数σ2 再次调节边框高和宽,使其向外扩展一点,使用扩展边框外部的点作为负样本(原文是除了正区域外的,被assign的整个feature map区域,作为负样本),这样将两个边框范围内的点忽略掉,增加正负样本之间的判别度。
σ1 是缩放因子,处于正区域范围内的单元会在训练的时候被标上相应类别标签。而另外一个缩放因子 σ2会被用在制定负区域,同样的计算方式(实验中采用的是σ1=0.3,σ2=0.4)。与此同时,需要注意此时的正样本只占了一小部分,为了克服正负样本不均衡,在分类任务中采用了Focal loss。
Box Prediction
关于Box 的回归,作者是通过下面那个分支,每个点会预测出(tx1,ty1,tx2,ty2)。其中(x1,y1,x2,y2)表示ground truth坐标,(x,y)表示一个cell单元的坐标,z为标准化因子使得输出空间映射到以1为中心的新空间
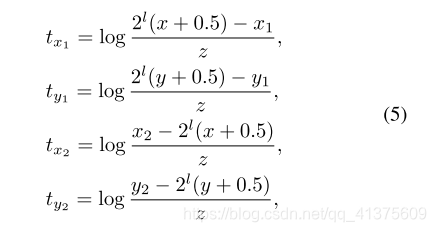
在本篇文章中,采用的是Smooth L1 loss
学习资料:
FoevaBox优质博客