论文:RepPoints: Point Set Representation for Object Detection
论文链接:https://arxiv.org/pdf/1904.11490.pdf
代码链接:https://github.com/microsoft/RepPoints
Preface
该篇文章是由微软亚研院提出,可以看做是可形变卷积的第三版本,文章相比之前的文章更难理解一些,本人理解可能也有偏差,大家可以多搜索些资料,积极思考下,本文仅给出个人阅读的见解。下面是一些阅读资料。
如何评价Deformable Conv
如何评价RepPoints
以及本文主要借鉴的一篇博客:
陀飞轮—RepPoints:可形变卷积的进阶
Review of DCNv1 and DCNv2
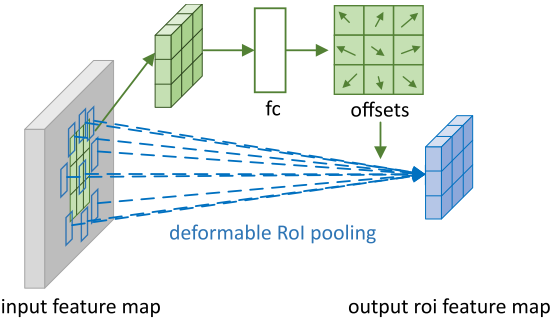
由尺度、姿态、视角和部分形变等因素引起的几何变化是目标识别和检测的主要挑战。在卷积/RoI池化模块中,DCN通过学习采样点的位置来得到几何形变建模的能力。
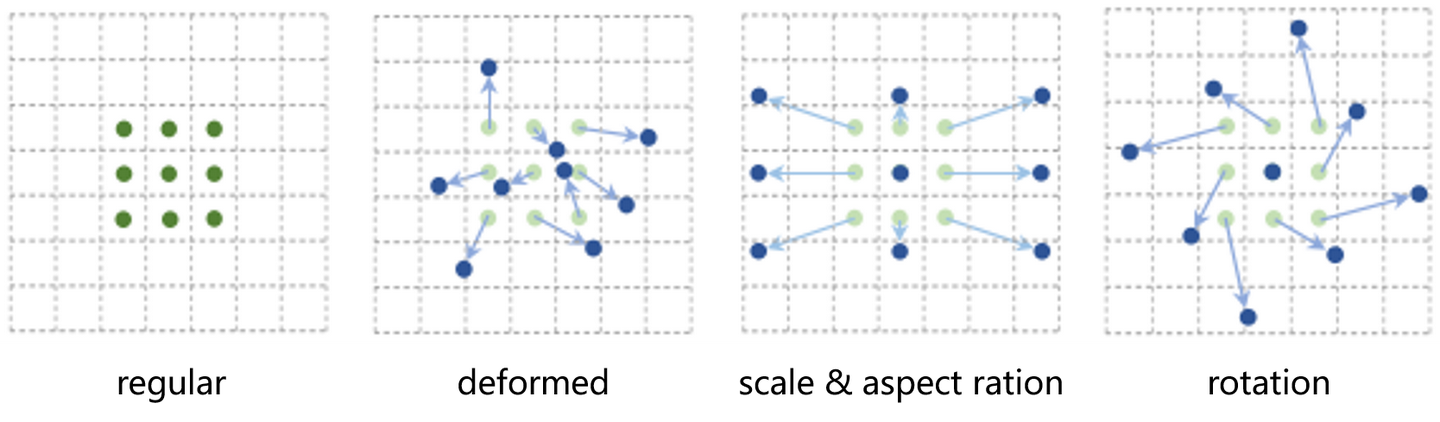
Deformable Convolution
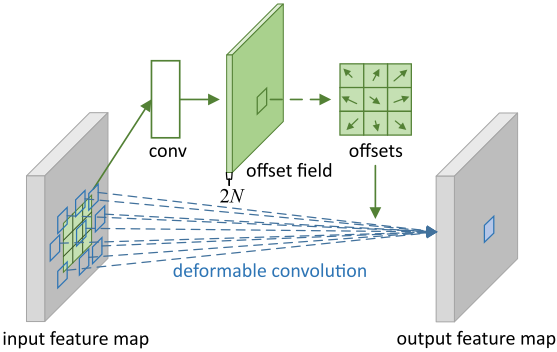
由输入特征学习得到的偏移量来改变标准卷积的采样位置。
可形变卷积可以表示为:
[具体的解释可见上述链接]
PS:偏移量特征的分辨率与输入特征的分辨率相同,且通道数为采样点个数的两倍(即每个位置都有x和y两个方向的偏移量)。
Modulated Deformable Convolution
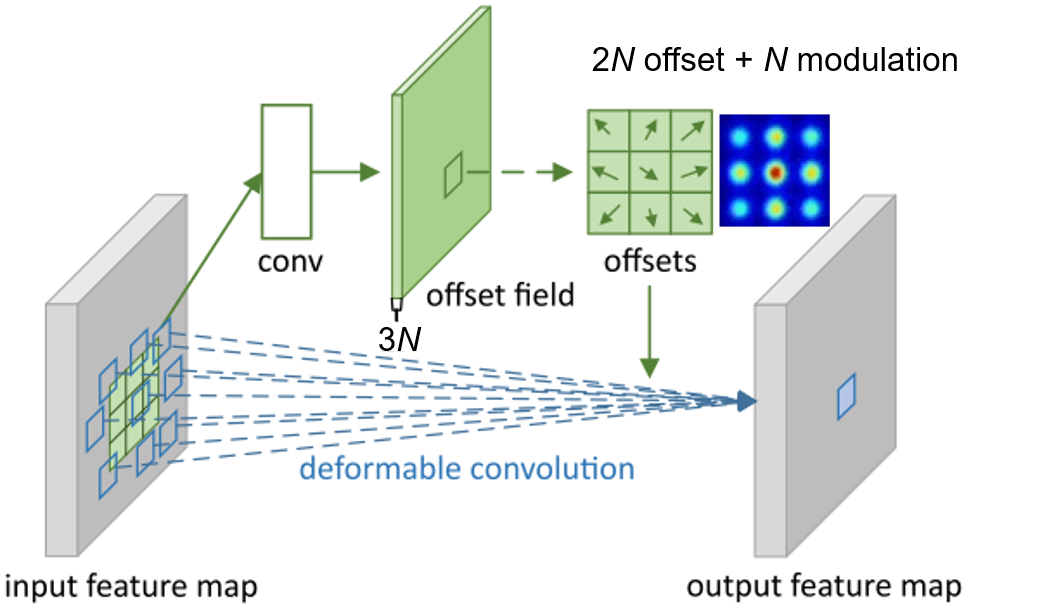
相比可形变卷积多了一个调制因子。
调制可形变卷积可以表示为:
PS:调制因子特征的分辨率与输入特征的分辨率相同,且通道数为采样点的个数,加上偏移量特征后的通道数为采样点个数的三倍(即每个位置都有x和y两个方向的偏移量,还有一个调制因子)。
Deformable RoI Pooling
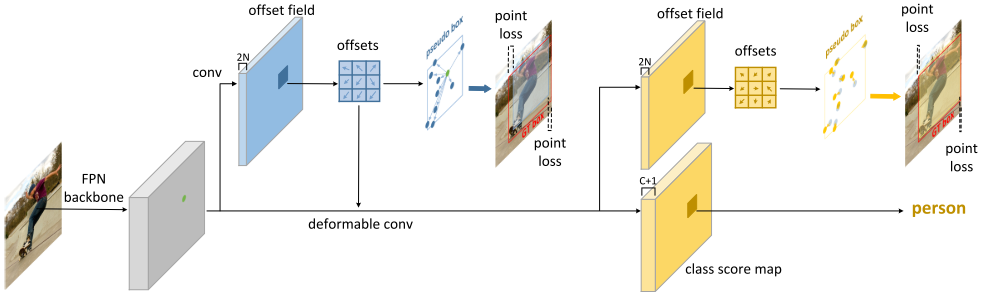
RepPoints
Motivation
在目标检测任务中,边界框描述了目标检测器各阶段的目标位置。
虽然边界框便于计算,但它们仅提供目标的粗略定位,并不完全拟合目标的形状和姿态。因此,从边界框的规则单元格中提取的特征可能会受到背景内容或前景区域的无效信息的严重影响。这可能导致特征质量降低,从而降低了目标检测的分类性能。
本文提出一种新的表示方法,称为 RepPoints,它提供了更细粒度的定位和更方便的分类。
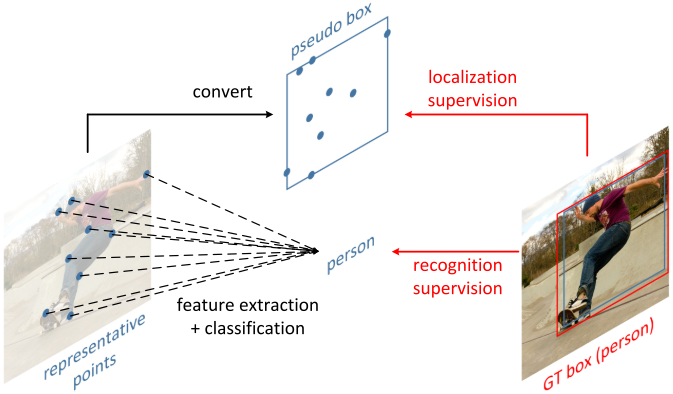
如图所示,RepPoints 是一组点,通过学习自适应地将自己置于目标之上,该方式限定了目标的空间范围,并且表示具有重要语义信息的局部区域。
RepPoints 的训练由目标定位和识别共同驱动的,因此,RepPoints 与 ground-truth 的边界框紧密相关,并引导检测器正确地分类目标。
Bounding Box Representation
边界框是一个4维表示,编码目标的空间位置,即 ,
表示中心点,
表示宽度和高度。
由于其使用简单方便,现代目标检测器严重依赖于边界框来表示检测 pipeline 中各个阶段的对象。
性能最优的目标检测器通常遵循一个 multi-stage 的识别范式,其中目标定位是逐步细化的。其中,目标表示的角色如下: